Inform 7 is used in a number of contexts that may be slightly surprising to its text adventure fans: in education, in prototyping game systems for commercial games, and lately even for machine learning research.
TextWorld: A Learning Environment for Text-Based Games documents how the researchers from Tilburg University, McGill University, and Microsoft Research built text adventure worlds with Inform 7 as part of an experiment in reinforcement learning.
Reinforcement learning is a machine learning strategy in which the ML agent gives inputs to a system (which might be a game that you’re training it to play well) and receives back a score on whether the input caused good or bad results. This score is the “reinforcement” part of the loop. Based on the cumulative scoring, the system readjusts its approach. Over many attempts to play the same game, the agent is trained to play better and better: it develops a policy, a mapping between current state and the action it should perform next.
With reinforcement learning, beacuse you’re relying on the game (or other system) to provide the training feedback dynamically, you don’t need to start your machine learning process with a big stack of pre-labeled data, and you don’t need a human being to understand the system before beginning to train. Reinforcement learning has been used to good effect in training computer agents to play Atari 2600 games.
Using this method with text adventures is dramatically more challenging, though, for a number of reasons:
- there are many more types of valid input than in the typical arcade game (the “action space”) and those actions are described in language (though the authors note the value of work such as that of BYU researchers Fulda et al in figuring out what verbs could sensibly be applied to a given noun)
- world state is communicated back in language (the “observational space”), and may be incompletely conveyed to the player, with lots of hidden state
- goals often need to be inferred by the player (“oh, I guess I’m trying to get that useful object from Aunt Jemima”)
- many Atari 2600 games have frequent changes of score or frequent death, providing a constant signal of feedback, whereas not all progress in a text adventure is rewarded by a score change, and solving a puzzle may require many moves that are not individually scored
TextWorld’s authors feel we’re not yet ready to train a machine agent to solve a hand-authored IF game like Zork — and they’ve documented the challenges here much more extensively than my rewording above. What they have done instead is to build a sandbox environment that does a more predictable subset of text adventure behavior. TextWorld is able to automatically generate games containing a lot of the standard puzzles:

Their system works out a set of objects and puzzles, generates Inform 7 code to describe these, compiles a game, and then has the ML agent play the resulting game:
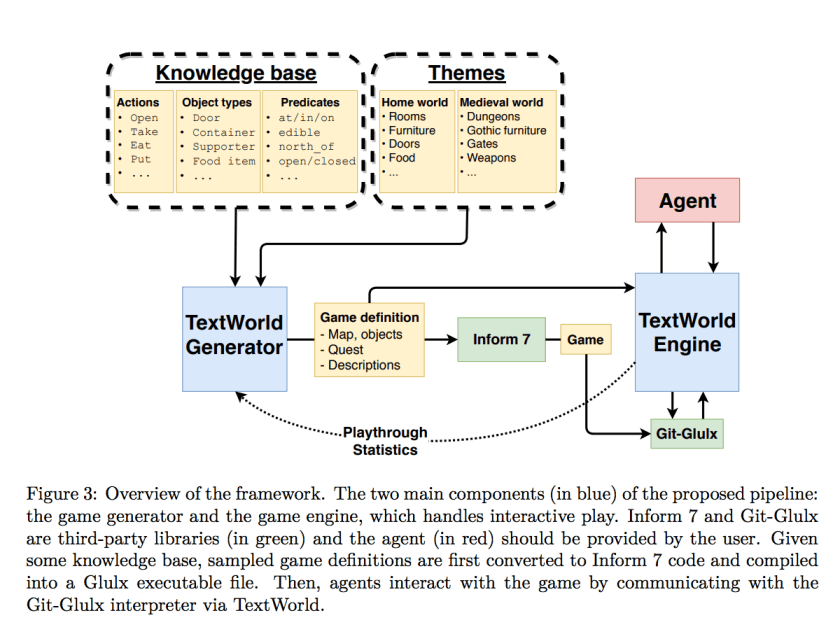
They’re also using some simple text generation to build the descriptions of objects and rooms you encounter.
To make a system basic enough for reinforcement learning, the authors pare back to situations that human players would find depressingly basic: rooms with objects lying on the floor to pick up; perhaps a single container or two. But the groundwork is here for more complicated challenges.
The article includes an analysis (Appendix A) of standard text adventure puzzles, and a chart (Appendix B) of most Infocom games and a number of more modern-era puzzlefests, breaking down which types of puzzles are present in each. The researchers also found the zarfian cruelty scale useful, and include cruelty ratings in the chart, perhaps because a cruel game may lead an ML agent into a training dead-end where it cannot progress but also cannot detect that it’s stuck.
*
See also this masters’ thesis by Mikulas Zelinka on reinforcement learning to play text-based games; on automatic puzzle generation within text or graphical adventure tropes, see Clara Fernandez-Vara’s work on the puzzle dice system.

For those who may not have ACM access, Clara Fernández-Vara’s paper is also available on MIT’s open access site: https://dspace.mit.edu/handle/1721.1/100267