I use similar methods when working out the large-scale design for a storylet project to do the following things:
Represent the story concept from start to finish
Distinguish sections of content that are fairly open and player-controlled from sections that are fairly tight
Distinguish sections that reuse shared parts of the storylet world from sections that are unique to just this narrative arc
Sometimes storylet passages can be very linear indeed — essentially a straight progression from one storylet to the next.
Alternatively, they can be highly freeform, with a bunch of randomly selected story beats that can advance the player’s goals, move them backwards, or cause/alleviate menaces.
This is a slightly unusual mailbag post because the question was asked in chat context, but it turned out to be something where I felt a number of other people would be interested in the answer, so I’ve paraphrased and expanded what I said there.
I have a story point where the protagonist has to do something. It feels bad not to offer them any choice here, but if they don’t do the thing, then the whole plot comes apart.
I have a bunch of tactics to offer here, depending on where in the story this is happening and what it means.
Tricks for the start of a story
What Lies Beneath the Clock Tower is partly about engagement vs withdrawal, and its start-of-adventure choice has more thematic validity than most
Start the story after the choice has been made. “The protagonist has to do this thing” is a pretty common situation at the beginning of a game where we’re looking at the inciting incident for the story. You usually don’t want to allow the player to choose not to go on the quest for Smaug’s gold. It’s better to assume that, if the player’s started a game about this quest, they want to play the quest, and we should just get on with the first interesting choice that happens after they’ve already committed.
There are very occasional cases where I think an aesthetic argument can be made for including such a choice, but they’re very much the exception.
Tricks that work later
Shift responsibility for the incident. You can decide that some other, external force is responsible for the protagonist’s bad situation — which may then require some setup to prepare. This often works fine in an action/adventure-y scenario where we expect that misadventures will regularly occur to motivate the plot.
Alternatively, we can make the bad twist into an unforeseeable but inevitable result of an action that was perfectly sensible for the protagonist to do. Perhaps they’ve rescued a puppy, in line with their characterization as a lover of animals, only this particular puppy is the carrier of a disease that sickens all the other animals in the shelter. This is where the idea of the expectation gap becomes useful.
Provide strong motivation in the choice framing. The more one digs into this, the more the difference between interactive and non-interactive story starts to melt away. A non-interactive story can force its protagonist to do something stupid on command — but the viewer still wants to understand that this act is in character.
Maybe the protagonist did steal a car and take it for a joy ride and get arrested — but they did that because it’s a flashy sports car that their asshole brother bought and drove to Thanksgiving dinner just to show off how much better he’s doing, and it pushed all of the protagonist’s buttons at once.
The thing is that if you put that same level and quality of setup into an interactive story, and then you offer the player the choice
Eat my turkey, keep my mouth shut
Join Dad in congratulating Ryan on his brilliant career choices
Pretend I need to pee, go outside, break into Ryan’s Porsche and drive it to Vegas
…there are pretty decent odds they will want to choose three.
And, if not, it’s also likely they’ll understand what the interface is communicating about the character if it’s greyed out the first two options as unavailable.
Dialogue in Neo Cab can be available or unavailable depending on the protagonist’s evolving mood. Disallowed choices options are conventional enough that most players will understand — even if the protagonist is actually forced to be in one specific mood at the key moment when you want to control their actions.
Skip the moment of decision. Use an act break or the space between episodes to skip ahead in the story until after the protagonist has done this.
This effect is distancing. The previous approach asks the player to think as much as possible in character with the protagonist, adopting their motivations and feelings so much that they do something that might not be in their own interests. This one, by contrast, pushes the player out of the protagonist’s head. Both can work, but they achieve different things.
You then do still need to reconcile the player to what’s just happened, though — justifying the protagonist at least in retrospect is often going to be critical to the player’s sense of themselves.
(I think my all-time least-favorite example of this is in Emily is Away, where control of the relationship is taken from the player in such a way that the protagonist engages in what could be construed as a dubiously consensual situation.)
One form of reconciliation is to make a mystery out of why the protagonist did this, and have the explanation gradually emerge through the next segment of play. I urge you not to motivate this via amnesia unless you absolutely have to, though.
Another approach is to show the aftermath of the Bad Choice, then tell what led to it in flashback. Think of all the TV shows that start with a shocking incident, then go back with “72 hours earlier…” to show how we got there. It’s a bit hackneyed, but it can work; and telling part of an interactive story in flashback mode means that we can ask some different types of question during this part of the story.
Which brings us to…
Useful any time
Offer a form of choice other than “what do you do?” Here are things you can ask the player instead:
How do you do this? Questions of method rather than intent are really common in Choice of Games works, and they feed into protagonism/identification forms of agency generally.
With what resources / at what cost / with what benefit? A bit related to “how,” but this choice gets the player engaged with the stakes of this part of the story.
Why do you do it? Motivation questions allow the player to put their own spin on an event. At the start of the game, this kind of question might let the player pick a backstory for their protagonist; later, it might have some other functions, like setting a new goal or calling back to a previous story outcome.
How do you feel about it afterward? A reflectivechoice with a slightly different flavor than the motivation question, often good to use as a character beat or a quiet moment between more action-y elements.
And then there are a few more esoteric options:
When, where, or with whom do you do this? All of your standard journalism questions are fair game for a choice point. And when/where/with whom questions can be good setup for an exploration or investigation sequence. Where do you go first? is a very common choice in a mystery scenario.
If there isn’t an obvious exploratory meaning, though, these questions may take a bit of framing to make them interesting — why does it matter where the player does the action? The answer to that might vary a lot depending on the narrative.
Sometimes from a narrative point of view it’s easier to think of these as resource/cost/benefit questions that just happen to be pegged to secondary characters or in-world locations.
You do this. What is the result? This one really flips the script, and sometimes it will feel deeply weird. But it can be a way to invite the player to co-authorship (at the more extreme/daring end of the spectrum). Alternatively, especially at the beginning of play, it can again let the player establish something about their protagonist’s family and home life. An example:
You put on a black leather corset with the red ribbon ties, and head for the front door. At which point…
Mom completely flips out — something about the fate awaiting all immodest women — but I’ve heard it before.
Mom completely flips out — wearing real leather is going to destroy the planet! — but I’ve heard it before.
Mom doesn’t look up from her laptop long enough to notice.
The corsetry event always happens, with whatever inevitable consequence, but we’ve given the player the chance to pick one of three possible conflict engines with the protagonist’s mother: she’s a workaholic too busy to give us attention, she’s conservatively controlling, or her ecology-focused activism makes her hard to live with.
Storylets encourage narrative designers to think in terms of systems, and allow story arcs to affect one another in memorable ways.
In my previous post on storylets, I showed how storylets can replicate standard interactive narrative structures that are familiar from video games or CYOA.
This post gets into the other things storylets can do for your narrative structure that would be harder to achieve with a conventional method. Specifically, storylets let you build a system where
episodic stories can feed into a larger narrative arc, and it’s easy to add new episodic content without ripping out all the existing stuff
the player is guided within, but not constrained to, a story they’re currently playing
different episodes interact with each other in fictionally and mechanically interesting ways
To take those one at a time:
Large and small narrative arcs
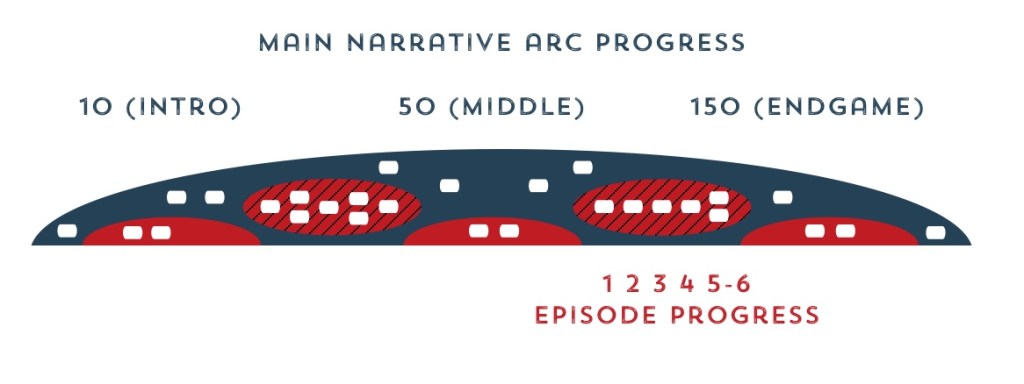
A big storylet-based story might have a long narrative arc and then a bunch of smaller internal stories inside it.
Bee was written for the Varytale platform, which is, alas, no longer available.
My game Bee, for instance, takes place over several years of the protagonist’s life. There’s an overall arc about her growing up until she’s no longer eligible for any more spelling bees, and the changes in her life that go alongside that. Within each year of her life, she experiences traditional holidays, trains, does chores, and develops relationships with the members of her family.
To track where the player is in this story, I tracked several different progress stats:
How many years have passed?
What month is it?
How far has she progressed with character relationships and their associated story arcs?
“How many years have passed?” controls high level progress through the story. When it reaches a high enough number, we’ll get to the endgame, a story about her last spelling bee ever.
“What month is it?” makes seasonal content available, and of course advances the year count. This means that
A storylet about Christmas has “month=December” as a prerequisite
Every storylet advances the month after it’s played, as an effect
If the month is December, the new month becomes January and the year stat is also advanced by 1
The character relationships, meanwhile, are mostly detached from those temporal measures. A player might progress rapidly through all the stages of a character story during the first “year” of the main narrative.
To generalize from that a bit, we can have episodic progress stats that track where we are in a small story (like the character relationships) and other stats that rise more slowly, or have much larger values, that track our progress through the main narrative arc:
In some games, completing an episode is what drives the main arc forward. Neo Cab works a bit along these lines: you can pick up 3-4 passengers a night, and it’s up to you which ones you want to drive.
But when you’ve ended your shift, the day ends and your overall progress ratchets forward, opening up new elements in the main storyline.
Guided but not constrained
A branching narrative struggles to tell the player more than one story at a time. Typically, the player has a tightly defined set of options at any given moment.
Conversely, parser-based text adventures and a lot of open world games can confront the player with a bewildering amount of freedom, leaving them unsure what they ought to do.
A storylet system can offer a happy medium here: contextually relevant options from all the stories you’re currently in the middle of, plus any “always available” elements. Making this comfortable for the player depends on some good UI design, as well, but the underlying system supports it.
Stories that interlock
Month, year, and character story progress are not the only stats in Bee. The game also tracks spelling skill, motivation, and family poverty.
These other stats aren’t progress stats, though. Motivation and spelling skill are resources. The protagonist needs motivation to be able to play certain storylets that improve spelling skill. And she needs spelling skill at a certain level to be able to pass the end of year spelling bee.
Meanwhile, poverty is a menace — something the player doesn’t want to increase, but which may rise as a result of events in the story. When poverty is too great, certain storylet options become unavailable, and others open up.
Seasonal events in Fallen London introduce new happenings in existing game locations, and unlock new elements within existing storylines.
This is still a fairly systems-light representation — other storylet games have lots of resources and menaces in play. In Sunless Skies, for instance, gaining too much terror unlocks Nightmare storylets that plague the protagonist with unspeakable visions.
Thanks to these abstractions, one story can meaningfully affect what happens in another.
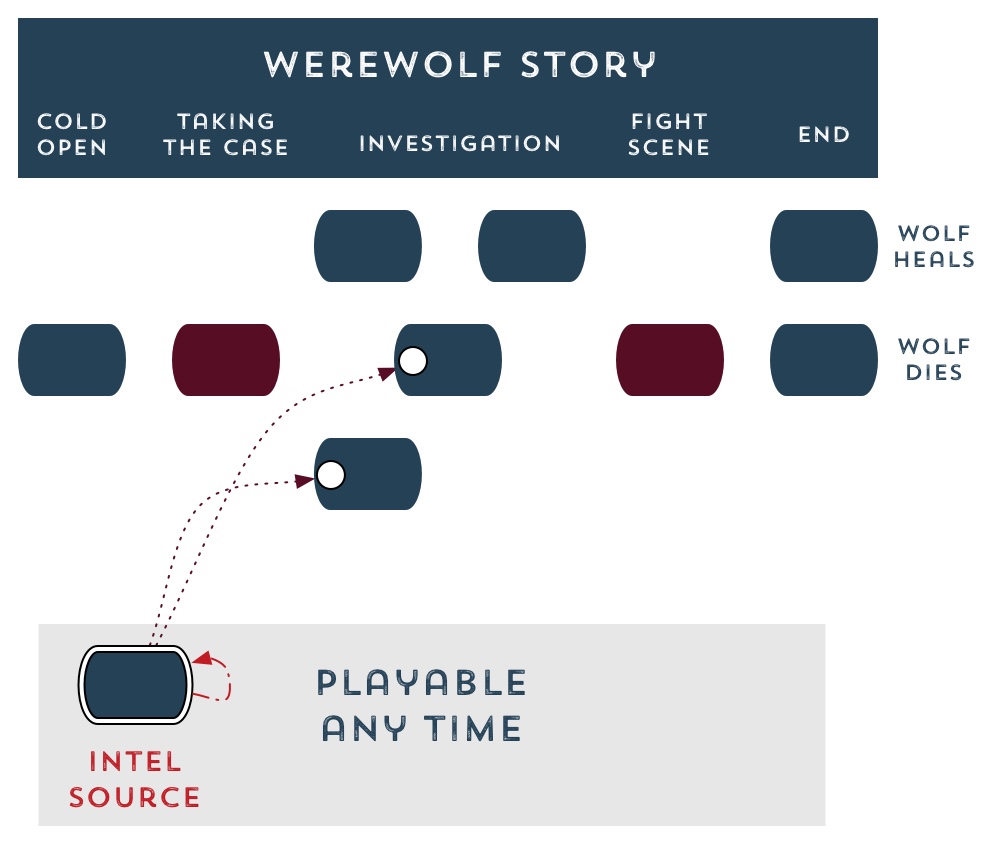
Here’s the branch and bottleneck storylet diagram from last post, except this time we’re including the idea that the player will sometimes need to go outside the episodic story she’s in if she wants to get the means to unlock the next episode. And conversely, sometimes she might need to do some other, unrelated activity to prevent a menace stat from going too high:
Some lovely storytelling dynamics can arise from systems like this, dynamics that echo the effects you find in long-running series television.
Suppose this episode is about tracking down a family of werewolves, but in order to unlock a midgame storylet, Mulder needs clues from an informant. That’s his source stat. Fortunately, he already has an informant available, unlocked through earlier play. He does have to go back through a familiar action or two of putting a signal in his apartment window in order to get his informant to show up — but that’s the kind of content reuse that feels fictionally justified.
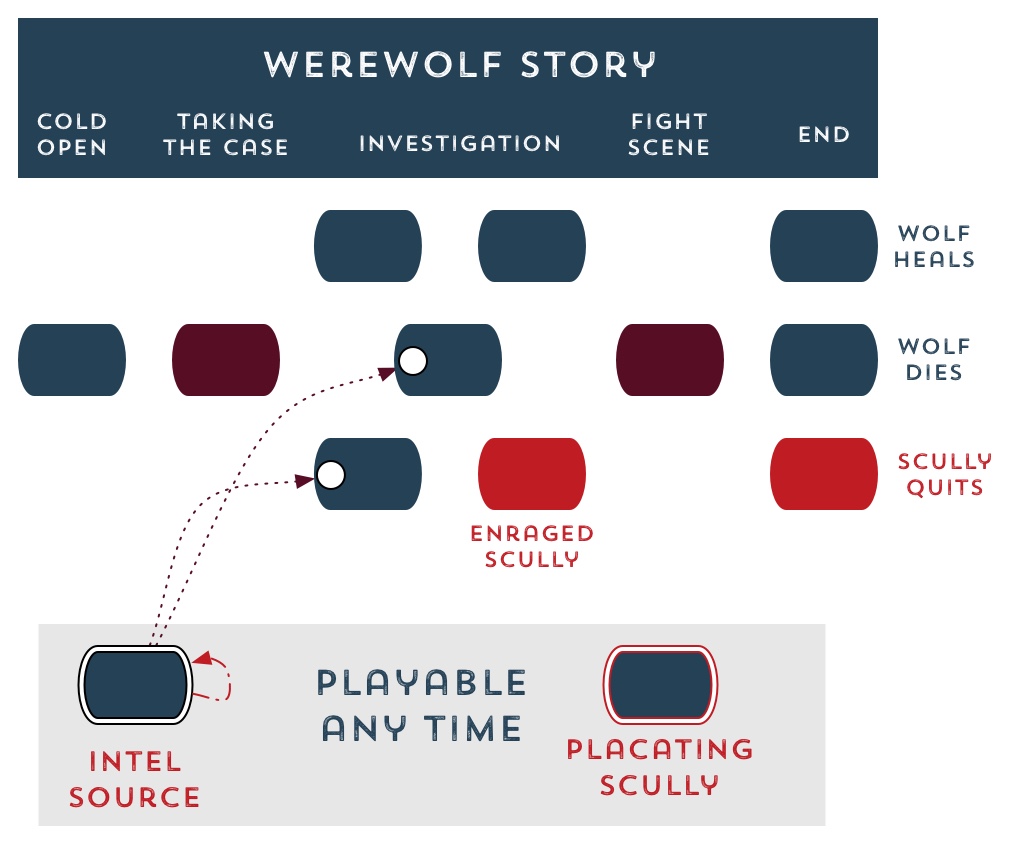
Now suppose that in the midgame, one storylet has Mulder insist on sitting out in the woods in a convertible to watch the full moon. But nothing happens all night long except they get a lot of mosquito bites, and in the morning the menace stat “Agent Scully’s Exasperation” ticks upward a little. Or a lot.
Now Scully’s exasperation score unlocks a whole new episode when this one is over, a Mulder-and-Scully-fight episode. Alternatively, Mulder realizes he’s gotten himself into trouble and engages in a menace-reducing activity of buying her an apology gift, as a beat between the plot beats of continuing to hunt werewolves.
All of those are elements that someone could bake into a traditional branching narrative as options at the critical points. But building the system of storylets means that there’s a whole reusable economy of menaces and resources.
It means that I could have holiday seasonal events where Mulder has extra options for cheering Scully up on her birthday, or where she’ll read his intentions differently if it’s around Valentine’s Day.
Or maybe the identity of Mulder’s informant changes depending on what has happened in the top-level narrative progression. Maybe any informant will do for getting the Information resource commodity, but the costs of doing so and the fictional tonality of the interaction shift a lot.
In fact, we might have a scenario where there are multiple sources available for information, and the player has to decide how long Mulder will spend investigating each of the sources before trying to move on from this point — the more intel-gathering storylets he plays, the better the outcome he can unlock:
…but other things might be happening at the same time. Menaces might be climbing; a time stat might be counting down.
At its core, this is standard game systems design advice: make sure your systems affect each other.
It’s possible to design with this kind of systems thinking in mind for (say) a branching narrative system, but storylets make it particularly natural to do so because they foreground the stats — what are you tracking? Which storylets become available, and which are locked, as a result?
This presentation by Tadhg Kelly, and this post on his blog, talk about four kinds of numbers in games — currencies, metrics, tools, and territory. Some of his definitions feel a little alien to me — I wouldn’t think of a tennis ball as a currency in the game of tennis. But using these broad categories and thinking about how they apply to stats in narrative design, we might divide them like this:
Progress stats, menaces, reputation, and relationship stats are metrics, advancing the storyline and opening up optional events.
Money, inventory items, consumable “favors owed” by other characters, and subtler items like energy are all currencies. Currencies are most fun if they have a backstory: the currency of Hell might not be acceptable to churchgoers. Creating fungible, convertible rewards allows different storylines to affect each other in fun and fictionally surprising ways.
Most of the storylet-based games I’ve played have at least some metrics and some currencies.
Some, but not all, also have a sense of territory — a stat representing the player’s location in the game universe, for instance. Territory works well with investigation or exploration gameplay where the player needs to figure out where to look next for something.
Tools, we might understand as things that open up new affordances and actions that wouldn’t otherwise be there.
Some storylet games use personality traits or skills this way, for instance by letting the player learn lockpicking in order to defeat any forthcoming locks. The challenge is that, to pay off properly, this really requires the content creators to be disciplined and make sure that there are regular opportunities to show off a particular skill or trait throughout the rest of the content. (There are procedural ways to help make sure that’s the case; that’s a more advanced design solution, though.)
Another interesting but less common way to design “tools” in a storylet system is to have something that affects how other options play out.
Reduce risk. Fallen London gives the player a supply of “second chances”, a resource the player can spend to guarantee herself a second roll of the dice on a risky attempt where she wants to increase her chance of succeeding.
Modify core metric stats. Inventory items and outfits might increase the player’s stats in particular areas, temporarily making certain storylets accessible.
Multiply / divide consequences. Make a storylet produce double the currency that it otherwise would! Make a compliment twice as effective on your relationship stats with the Countess! Etc.
Storylet systems are a way of organizing narrative content with more flexibility than the typical branching narrative.
Very frequently, when I’m called in to suggest a narrative delivery system that will work for a particular game, I find myself sketching out some form of storylet-based solution. Storylets are simple, atomic, robust, and recombinable.
Here’s my basic definition of a storylet (though many systems may call them other things: events, snippets, etc):
there is a piece of content. It might be a line or a whole section of dialogue, it might be narration, it might be an animation or scrap of film
there are prerequisites that determine when the content can play
there are effects on the world state that result after the content has played
I’ve written some before about how this structure lets one get beyond standard branching narrative, with quality-based and salience-based structures. It is the concept underlying StoryNexus. It also underlies Threaded Conversation, the conversation library I wrote for Inform (eventually released, and now maintained, by Chris Conley).
You could even understand conversation elements in Versu and in Character Engine as a type of storylet. In those cases, there is quite a lot of other procedural work determining what content should be presented next and how it should vary. Quite a few procedural narrative systems work by defining some kind of model for stringing storylets together — so this can be an approach that will support an ambitious AI-driven concept.
At the same time, this design method isn’t only for the procedurally ambitious. You can make and explore the affordances of a rudimentary storylet system by writing your storylet content and quality rules on a set of index cards. And in fact I do sometimes do exactly that as a paper prototyping exercise.
This definition leaves a lot else out. It doesn’t say how much content is inside a given storylet, how that content is structured, or how it’s selected. Max Kreminski’s overview work explores a lot of the nuances here.
But for the present article, I’m looking chiefly at how many standard ways of structuring game narrative content can be rendered in storylets.
Common Branching Structures and Storylets
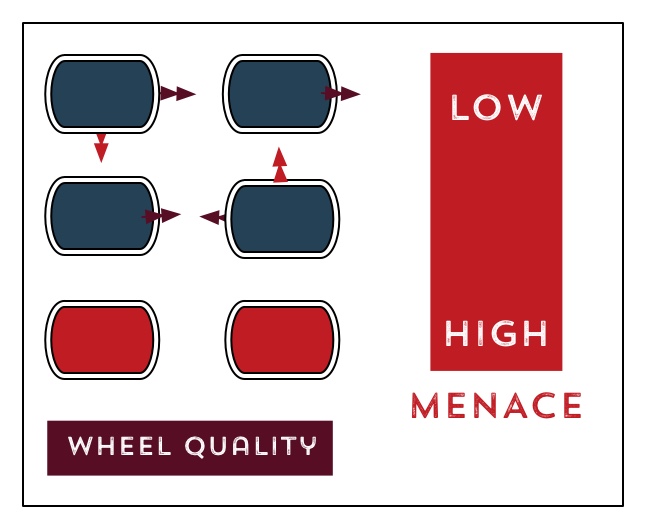
Storylets can be used to replicate a lot of classic structures from branching, Twine, or Choose Your Own Adventure contexts, if you give yourself a progress stat or quality to count how far you are through the story, and perhaps also allow for a menace stat to represent how much trouble the player is in.
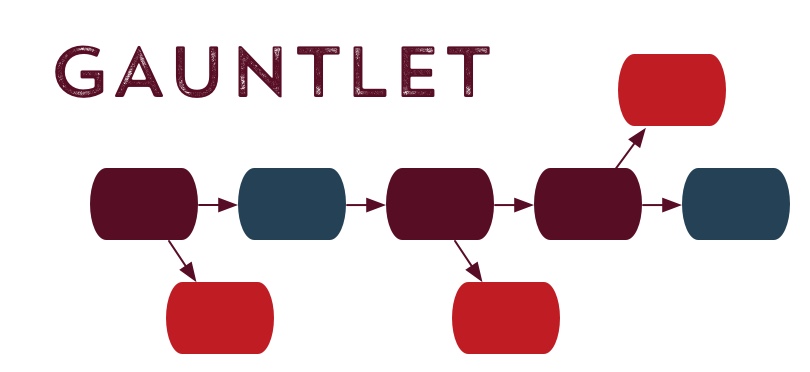
For instance, here’s a gauntlet storyline, linear except where the player makes a mistake, as it might be represented in Twine and then as it might be represented in storylets:
This is actually a reprint of a comment exchange that appeared earlier on this blog, but it’s the kind of question that I typically mailbag, so I’m reproducing it here for visibility.
A question, if I may: I’m not much of a story-writer (as in coming up with the ‘adventure’ part of the equation), but I’m working on a densely interactive VR diorama (http://naam.itch.io/apotu) and a story/plot is starting to emerge from all the incidental detail popping up everywhere, taking shape in my head. It’s more of a situation/slice-of-life thing than a story per se. What would you (or any other reader!) say is a good way to come up with narrative cues to divulge this to the visitor?
I guess I’m mainly struggling with process – how to come up with just the right bits of information to relate to the listener, and how to make that matter.
Start by identifying the bare minimum. What are the 3-7 most important events or beats the player must know about in order to understand your story? What traces might those events have left on the world?
Twice this year I’ve spoken about matching story and mechanics — once for the Oxford/London IF Meetup, and once as a keynote talk at the Malta Global Game Jam. Both times, I mentioned the idea of using mechanics as the basis of world-building. I’ve done this both with the letter-changing powers of Counterfeit Monkey and the Lavori d’Aracne sympathetic magic of Savoir-Faire and Damnatio Memoriae. (I’ll talk a bit about all of those games below, so beware moderate spoilers, if you care.)
In Malta, one of the questions I got after my talk was “how do I know what questions to ask when world-building?” and I suggested having a look at conventional fiction guides for world-building. It seemed like a fair response at a time, but as I’ve had a look at some of the world-building guides out there, I felt that most of them didn’t necessarily translate directly to the types of strategies I use for this cause. So I’ll belatedly go into a little more depth about that now, in the hope it’s useful to someone (whether or not ever seen by the original questioner).
If you’ve got mechanics, that typically means you’ve got
an action/set of actions for the player to perform
some kind of world state that is affected by those actions in some way
And that’s all we need to ask world-building questions.








 Twice this year I’ve spoken about matching story and mechanics — once for the
Twice this year I’ve spoken about matching story and mechanics — once for the 